This page intends to explain ICA to researchers that want to understand it but only have a weak background both in matrix computation and information theory. My explanations will be as intuitive as possible and based on practical examples from Matlab. I would value your feedback on this page (contact me at arno
ICA is a technique to separate linearly mixed sources. For instance, let's try to mix and then separate two sources. Let's define the time courses of 2 independent sources A(top) and B(bottom) (see the Matlab code)
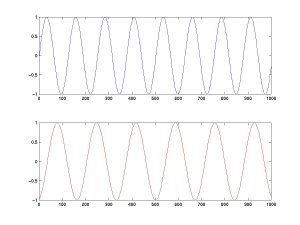
We then mix linearly these two sources. The top curve is equal to A minus twice B and the bottom the linear combination is 1.73*A +3.41*B.
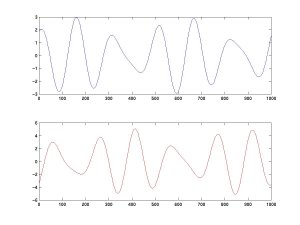
We then input these two signals into the ICA algorithm (in this case,
fastICA)
which is able to uncover the original activation of A and B.
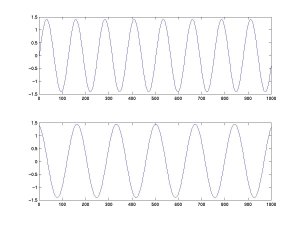
Note that the algorithm cannot recover the exact amplitude of the source
activities (we will see later why). I advice you to try this with different
degree of noise and see that it's quite robust. Note also that, in theory, ICA can
only extract sources that are combined linearly.
We will now explain the preprocessing performed by most ICA algorithms before actually applying ICA.
A first step in many ICA algorithms is to whiten (or sphere) the data. This means that we remove any correlations in the data, i.e. the different channels (matrix Q) are forced to be uncorrelated.
Why do that? A geometrical interpretation is that it restores the initial "shape" of the data and that then ICA must only rotate the resulting matrix (see below). Once more, let's mix two random sources A and B. At each time, in the following graph, the value of A is the abscisia of the data point and the value of B is their ordinates.
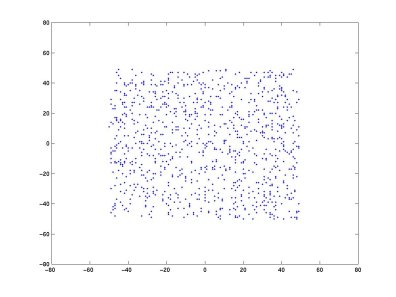
Let take two linear mixtures of A and B (see the Matlab code) and plot these two new variables
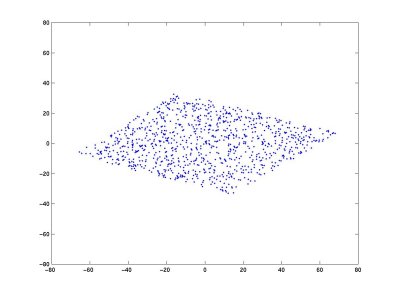
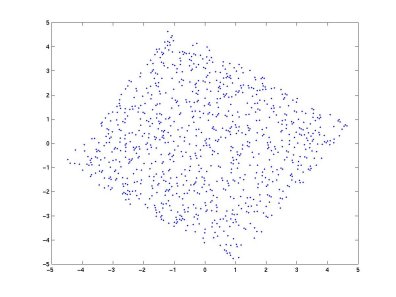
The whitening process is simply a linear change of coordinate of the
mixed data. Once the ICA solution is found in this "whitened" coordinate frame,
we can easilly reproject the ICA solution back into the original coordinate
frame.
Intuitively you can imagine that ICA rotates the whitened matrix back
to the original (A,B) space (first scatter plot above). It performs the rotation by
minimizing the Gaussianity of the data projected on both axes (fixed point
ICA). For instance, in the example above,
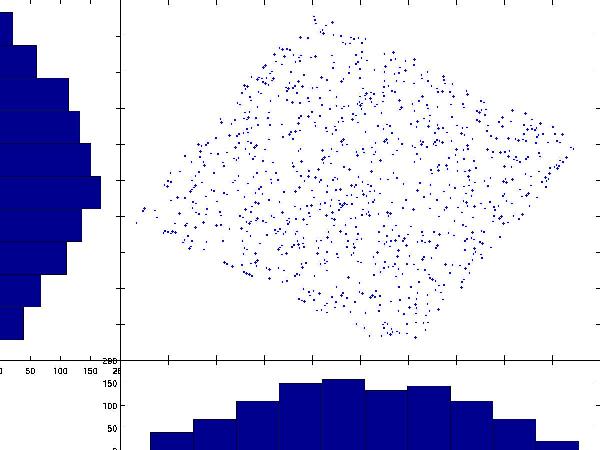
The projection on both axis is quite Gaussian (i.e., it looks like a bell
shape curve). By contrast the projection in the original A, B space far from gaussian.
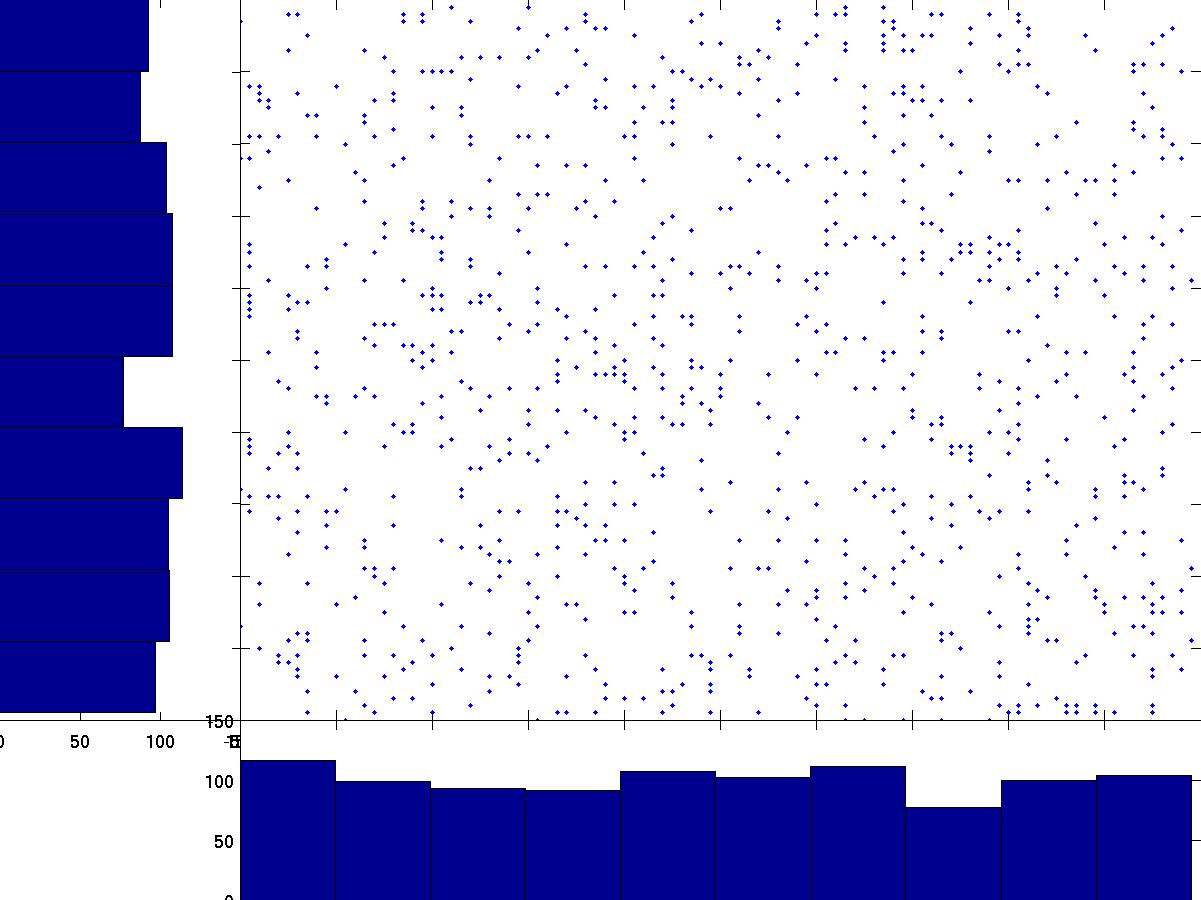
By rotating the axis and minimizing Gaussianity of the projection in
the first scatter plot,
ICA is able to recover the original sources which are statistically
independent (this property comes from the central limit theorem which states
that any linear mixture of 2 independent random variables is more Gaussian
than the original variables). In Matlab, the function kurtosis (kurt() in
the EEGLAB toolbox; kurtosis() in the Matlab statistical toolbox) gives an
indication of the gaussianity of a distribution (but the fixed-point ICA algorithm uses a slightly different measure called negentropy).
The Infomax ICA in the EEGLAB toolbox (Infomax ICA) is not as intuitive and involves minimizing the mutual information of the data projected on both axes.
However, even if ICA algorithms differ from a numerical point of view, they are all equivalent from a theoretical point of view (see Tee-won Lee publications).
ICA in N dimensions
We dealt with only 2 dimensions. However ICA can deal with an arbitrary high number of dimensions. Let's consider 128 EEG electrodes for instance. The signal recorded in all electrode at each time point then constitutes a data point in a 128 dimension space. After whitening the data, ICA will "rotate the 128 axis" in order to minimize the Gaussianity of the projection on all axis (note that unlinke PCA the axis do not have to remain orthogonal).
What we call ICA components is the matrix that allows projecting the data in the initial space to one of the axis found by ICA. The weight matrix is the full transformation from the original space. When we write
X is the data in the original space. For EEG
| Time points |
||
|
Electrodes 1 Electrodes 2 Electrodes 3 |
[ 0.134 0.424 0.653 0.739 0.932 0.183 0.834 ....] [ 0.314 0.154 0.732 0.932 0.183 0.834 0.134 ....] [ 0.824 0.534 0.314 0.654 0.739 0.932 0.183 ....] |
For fMRI
| Voxels |
||
|
Time 1 Time 2 Time 3 |
[ 0.134 0.424 0.653 0.739 0.932 0.183 0.834 ....] [ 0.314 0.154 0.732 0.932 0.183 0.834 0.134 ....] [ 0.824 0.534 0.314 0.654 0.739 0.932 0.183 ....] |
S is the source activity.
In EEG: An artifact time course or the time course of the one compact domain in the brain
| Time points |
||
|
Component 1 Component 2 Component 3 |
[ 0.824 0.534 0.314 0.654 0.739 0.932 0.183
....] [ 0.314 0.154 0.732 0.932 0.183 0.834 0.134 ....] [ 0.153 0.734 0.134 0.324 0.654 0.739 0.932 ....] |
In fMRI: An artifact topography or the topography of statistically maximally independent pattern of activation
W is the weight matrix to go from the S space to the X space.
Now the rows of W are the vector with which we can compute the activity of one independent component. To compute, the component activity in the formula S = W X, the weight matrix W is defined as (note if the linear transformation between X and S is still unclear (that is if you do not know how to perform matrix multiplication), look up this book is a good starting point).
|
Component 1 Component 2 Component 3 |
elec1 elec2 elec3 elec4 elec5
[ 0.824 0.534 0.314 0.654 0.739 ...]
[ 0.314 0.154 0.732 0.932 0.183 ...]
[ 0.153 0.734 0.134 0.324 0.654 ...]
|
|
Component 2 |
elec1 elec2 elec3 elec4 elec5
[ 0.314 0.154 0.732 0.932 0.183 ...]
|
Now you have the activity of the second component, but the activity is unitless. If you have heard of inverse modeling, the analogy with EEG/ERP sources in dipole localization software is the easiest to grasp. Each dipole has an activity (which project linearly to all electrodes). The activity of the Brain source (dipole) is unitless unless it is projected to the electrodes. So each dipole create a contribution at each electrode site. ICA components are just the same.
Now we will see how to reproject one component to the electrode space. W-1 is the inverse matrix to go from the source space S to the data space X.
|
Electrode 1 Electrode 2 Electrode 3 |
comp1 comp2 comp3 comp4 comp5
[ 0.184 0.253 0.131 0.364 0.639 ...]
[ 0.731 0.854 0.072 0.293 0.513 ...]
[ 0.125 0.374 0.914 0.134 0.465 ...]
|
|
Electrode 1 Electrode 2 Electrode 3 |
comp2
[ 0.253 ]
[ 0.854 ]
[ 0.374 ]
|
| (on the rigth one row of the S matrix (the activity of component 2) |
[ 0.314 0.154 0.732 0.932 0.183 0.834 0.134 ....] |
|
| [ 0.253 ] [ 0.854 ] [ 0.374 ] |
[ 0.824 0.534 0.314 0.654 0.739 0.932 0.183
....] [ 0.314 0.154 0.732 0.932 0.183 0.834 0.134
....]
[ 0.153 0.734 0.134 0.324 0.654 0.739 0.932
....]
(above is the projection of one component activity on all the electrodes (note that the calculus not accurate and that the numbers are meaningless). This matrix will be denoted XC2. |
Now, if one want to remove component number 2 from the data (for instance if component number 2 proved to be an artifact), one can simply subtract the matrix above (XC2) from the original data X.
Note that in the matrix computed above (XC2) all the columns are proportional, which mean that the scalp activity is simply scaled. For this reason, we denote the columns of the W-1 matrix, the scalp topography of the components. Each column of this matrix is the topography of one component which is scaled in time by the activity of the component. The scalp topography of each component can be used to estimate the equivalent dipole location for this component (assuming the component is not an artifact).
As a conclusion, when we talk about independent components, we usually refer to two concepts
- Rows of the S matrix which are the time course of the component activity
- Columns of the W-1 matrix which are the scalp projection
of the components
ICA properties
From the preceding paragraphs, several properties of ICA becomes obvious
- ICA can only separate linearly mixed sources.
- Since ICA is dealing with clouds of point, changing the order in which the points are plotted (the time points order in EEG) has virtually no effect on the outcome of the algorithm.
- Changing the channel order (for instance swapping electrode locations
in EEG) has also no effect on the outcome of the algorithm. For EEG, the
algorithm has no a priori about the electrode location and the fact that ICA
components can most of the time be resolved to a single equivalent dipole
is a proof that ICA is able to isolate compact domains of cortical synchrony.
- Since ICA separates sources by maximizing their non-Gaussianity, perfect Gaussian sources can not be separated
- Even when the sources are not independent, ICA finds a space where
they are maximally independents.
The necessary mathematical bases that will be assumed in the following are
- What is matrix and what is a vector
- How to multiply matrices; how to multiply vectors and matrices, vectors and vectors
- How to transpose a matrix
- What is the determinant of a matrix
- What is the covariance of a matrix
- What is a Jacobian (remind me)
Whitening the data in mathematical terms
Putting it in mathematical terms, we seek a linear transformation V of the data D such that when P = V*D we now have Cov(P) = I (I being the identity matrix, zeros everywhere and 1s in the Diagonal; Cov being the covariance). It thus means that all the rows of the transformed matrix are uncorrelated (see covariance matrix).
Let consider "centered" matrix Z of matrix D : Cov(D) = Cov(Z) = (Z*Z')/(n-1), (as defined previously z_i,j = d_i,j - mean(d_i))
Then it is easy to show that Cov(P) = I by setting V = C-1/2, where C = Cov(D) is the correlation matrix of the data, since then we have
Cov(P) = Cov( V*D )
= Cov( C-1/2*Z )
= C-1/2*Z*Z'*C-1/2 by definition
= C-1/2CC-1/2 = I.
(computing Cx is not an easy process: to simplify it is defined as to achive Cx*C-x = I and involve complex computation such as the determinant of the matrix....)
Maths on ICA coming soon...
For more information the most comprehensive reference to read is http://www.cis.hut.fi/aapo/papers/IJCNN99_tutorialweb/